AttentionViz: A Global View of Transformer Attention
Catherine Yeh, Yida Chen, Aoyu Wu, Cynthia Chen, Fernanda Viegas, Martin Wattenberg
DOI: 10.1109/TVCG.2023.3327163
Room: 106
2023-10-24T23:45:00ZGMT-0600Change your timezone on the schedule page
2023-10-24T23:45:00Z
Fast forward
Full Video
Keywords
Transformer, Attention, NLP, Computer Vision, Visual Analytics
Abstract
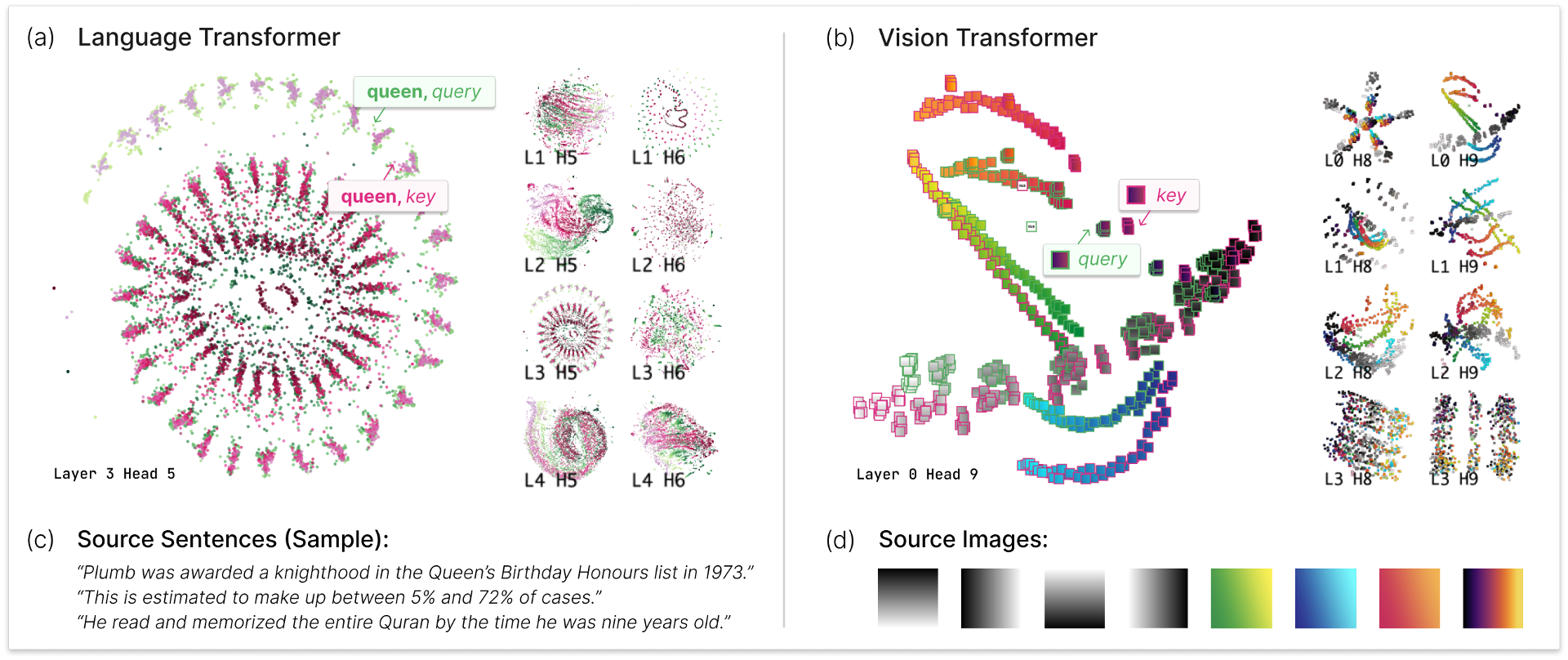
Transformer models are revolutionizing machine learning, but their inner workings remain mysterious. In this work, we present a new visualization technique designed to help researchers understand the self-attention mechanism in transformers that allows these models to learn rich, contextual relationships between elements of a sequence. The main idea behind our method is to visualize a joint embedding of the query and key vectors used by transformer models to compute attention. Unlike previous attention visualization techniques, our approach enables the analysis of global patterns across multiple input sequences. We create an interactive visualization tool, AttentionViz (demo: http://attentionviz.com), based on these joint query-key embeddings, and use it to study attention mechanisms in both language and vision transformers. We demonstrate the utility of our approach in improving model understanding and offering new insights about query-key interactions through several application scenarios and expert feedback.